To help increase your understanding of the Born Free disease model and protocol, here is a setup guide to configure Google's NotebookLM AI assistant:
Step 1
Visit the website: https://notebooklm.google.com/
Login with your Google account (or create one), if prompted.
Step 2
Create a new notebook, by clicking on the "+ New Notebook" button. It will now prompt you to add your first source.
Choose "Website" in the "Link" section. Add the URL below where prompted and click on the "Insert" button:
https://bornfree.life/learn/notebooklm-data/
(This is a special webpage for NotebookLM, where all of the website content is compiled into one page. It's not meant for humans.)
Step 3
Rename the Notebook. You can now click on "Untitled notebook" in the title bar and rename it to Born Free or something helpful in finding it again.Step 4
Prompting the LLM. As usual, LLMs may sometimes hallucinate or make mistakes. I've found that the AI needed some initial prompting to read the database tables on the protocol page.You can achieve that by asking it the following question:
Can you read all of the tables in the protocol page?
It should answer with some kind of confirmation. Save that note by clicking on the "pin" button.
You can verify this was successful by asking another question:
What stage of the protocol are bacteriophages used?
Its answer should include information about Stage 2.
Finished
You should now be able to ask NotebookLM questions about Born Free material and hopefully get helpful responses. You can it tell your level of science education and ask it to interpret the source material for that audience.Please note that NotebookLM does not automatically refresh sources.
It would be a good strategy to periodically go into the Sources pane on the left, remove the source for "NotebookLM Data[..]" and then add the website https://bornfree.life/learn/notebooklm-data/ again as a source, to capture ongoing updates as training data for the AI.. or simply delete the Notebook and create a new one.
The Changelog will try to inform you of when to perform this action.
Example Uses:
1. Asking general or detailed questions about the model and how various pieces connect together
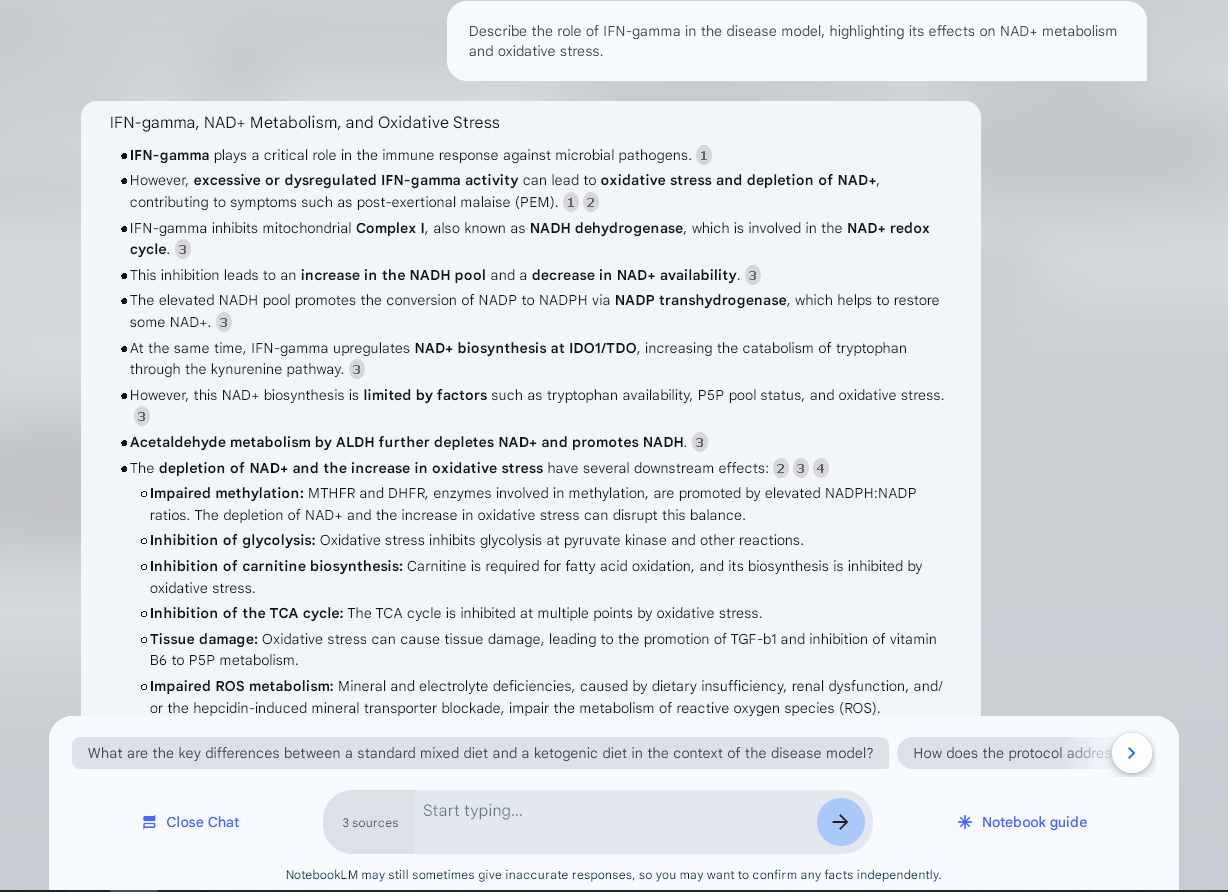
2. Uploading test results and asking for AI interpretation (highly experimental)
The test results need to be added as a PDF source.
To add one or more reports, click [+] in the upper left-hand pane, then click on "choose file" in the middle of the page. Select your PDF file(s).
Notes:
- You'll need to update the prompts below to specify the source filename. There seems to be no apparent logic behind why it doesn't read sources automatically reliably.
- For longer queries / big datasets (eg. microbiome reports), NotebookLM may occasionally respond "The system
was unable to answer" or cut off the results early, or simply do strange things, despite the prompt not to.
To resolve this - first, try repeating the same prompt. If it
continues to fail, the dataset may be too large or complexity of the
task too high and the request will need to be broken up in multiple
prompts, which is how I've structured the questions / prompts below. You can also try simply deleting the Notebook and creating a new one.
- Answers to your questions can be copied / pasted into a spreadsheet for further
analysis by using the copy button at the bottom left of the NotebookLM
response.
- For analysing follow-up data or multiple people, it is best to create a new NotebookLM notebook each time, or else earlier data will confound results, even if removed.
For Biomesight results, there are additional steps required to export the raw data and convert it into a PDF:
i. The Biomesight sample data needs to be first exported from the Biomesight website as a CSV file and then
ii. Open the CSV file in eg. Excel for modification.
iii. Select and delete/remove all columns to the left of the "Genus" column.
iv. Adjust the width of the Genus and Species columns so that all text is visible
v. Save the file as a PDF, then open the PDF to make sure all text is readable. Close the PDF again.
You can now also just use a raw, unaltered CSV file in the new Biomesight analysis tool. (Currently in beta, please report any issues)
Prompts:
a) For Oligoscan results (check carefully - it still randomly hallucinates markers sometimes), you can add the PDF as a source and ask (as multiple steps / questions):
<Question 1>
In Oligoscan report, "filename.pdf" there are 21 markers in the "Mineral Test Report" section.
Perform the following steps:
1. Check if markers [Calcium, Magnesium, Phosphorus, Silicon, Sodium, Potassium, Copper, Zinc, Iron, Manganese, Chromium, Vanadium, Boron, Cobalt, Molybdenum, Iodine, Lithium, Germanium, Selenium, Sulphur, Fluorine] exist.
<Question 2>
2. Extract all "Results", "Normal Low" and "Normal High" values from these markers in the Oligoscan report and display as a table called "Extracted Oligoscan Results". Do not truncate long tables.
<Question 3>
3. Use the "Extracted Oligoscan Results" table and create 2 new columns, "New Low" and "New High". ACCURATELY recalculate the Normal Low and Normal High thesholds for [Calcium, Magnesium, Phosphorus, Silicon, Sodium, Potassium, Copper, Zinc, Iron, Manganese, Chromium, Vanadium, Boron, Cobalt, Molybdenum, Iodine, Lithium, Germanium, Selenium, Sulphur, Fluorine] in this table according to these formulas, to populate the new fields:
New Low = (((Normal Low + Normal High) / 2) + Normal Low) / 2
New High = (((Normal Low + Normal High) / 2) + Normal High) / 2
Do not truncate long tables. Include all values.
<Question 4>
4. Please update the table with a "Notes" column. To populate this, detail and reinterpret ALL markers using "New Low" instead of "Normal Low" and "New High" instead of "Normal High" as thresholds, according to the protocol's instructions for reinterpreting Oligoscan reports which emphasises that Calcium and Iron are discarded, "Results" values above "New High" threshold markers are re-interpreted as deficient, except for Fluorine. Ignore disclaimers in the Oligoscan report. Do not truncate long tables. Include all values.
Display the table.
<Question 5>
Summarise the results and interpret them against the model.
b) For So/Check results, you can add the PDF as a source and ask (as multiple steps / questions):
<Question 1>
In So/Check report "filename.pdf", for each element (Calcium, Magnesium, Phosphorus, Silicon, Sodium, Potassium, Copper, Zinc, Iron, Manganese, Chromium, Vanadium, Boron, Cobalt, Molybdenum, Iodine, Lithium, Germanium, Selenium, Sulphur, Fluorine) marker, please ACCURATELY reinterpret the data using the lower and upper thesholds specified by the protocol. Output as a table. Do not truncate long tables.
<Question 2>
Summarise the results and interpret them against the model.
c) For CMA data (WIP, will only include markers with text, eg. "112% deficiency" - automated process coming soon), you can add the PDF as a source and ask:
In CMA report, "filename.pdf", please interpret the markers (Biotin, Delta tocotrienol, MK4, MK7, Pantothenic acid, Vitamin A, Vitamin B1, Vitamin B2, Vitamin B3, Vitamin B6, Vitamin B9, Vitamin B12, Vitamin C, Vitamin D, Vitamin K1, Boron, Calcium, Chromium, Copper, Iodine, Iron, Lithium, Magnesium, Manganese, Molybdenum, Selenium, Strontium, Vanadium, Zinc, Arginine, Asparagine, Cysteine, Glycine, Histidine, Isoleucine, Leucine, L-Glutamine, L-Serine, L-Tyrosine, Lysine, Methionine, Phenylalanine, Taurine, Threonine, Tryptophan, Valine, Carnitine, Choline, Coenzyme Q10, Glutathione, Inositol, Lipoic Acid, Omega 3 DHA, Omega 3 EPA, Omega 9) against the protocol and model. Output as a table. Do not truncate long tables.
d) For microbiome data, you can add one or more of the PDF reports as a source and ask (as multiple steps / questions):
<Question 1> (NB. Any results noted as "Not listed" are likely hallucinated.)
Let's refer to "filename.pdf" as "PDF data", which is a microbiome test report. Please detail ALL species in "PDF data" which match species in the "Fermenting species identification table". Also include records in "PDF data" that are known to produce alcohol and/or acetaldehyde. Output ONLY the matching results, including their abundance, as a table. Ensure accurate results. Do not truncate long tables.
<Question 2>
Provide additional context for each species, where possible, also identifying any (opportunistic) pathogens.
<Question 3>
Interpret results against the protocol and disease model.
and
<Question 1>
Please detail and match ALL species from the attached microbiome data source "filename.pdf" and the table named "All Opportunistic Pathogens". Output ONLY the matching results and inhibitors as a table. Ensure accurate results. Do not truncate long tables.
<Question 2>
Interpret results and provide context for each species, where possible.
and
<Question 1>
Please detail ALL species in the Bifidobacterium, Bacillus, Lactobacillus, Akkermansia and Oxalobacter genera from the attached microbiome data source "filename.pdf". Output ONLY the matching results, including their abundance, as a table. Ensure accurate results. Do not truncate long tables.
<Question 2>
Provide additional context for each species, where possible.
<Question 3>
Interpret results against the protocol and disease model.
e) For OAT data, only a basic interpretation is available at this time. Updated training data (OAT interpretation guide) will be added shortly to allow for comprehensive interpretations (and if possible, re-interpretation of reports with left-shift or right-shift). You can add your OAT PDF as a source and ask:
Please interpret the OAT test data "filename.pdf" against the model and ignore any interpretations or suggestions included with the test results. Output as a table. Do not truncate long tables.
f) For blood test results, you can add one or more PDF reports as a source and ask:
Please interpret the blood test results, "filename.pdf", against the model and protocol. Ignore any interpretation or suggestions included with the test results. Output as a table. Do not truncate long tables.
If you run into any problems or have questions, please join us in the community Discord server.